프로그래머스 코딩테스트 Lv.1 문제들
2023-04-10 ~ 05-02
푼 문제 : 달리기 경주, 추억 점수, 대충 만든 자판, 크레인 인형뽑기 게임, 문자열 나누기, 신규 아이디 추천, 성격 유형 검사하기, 개인정보 수집 유효기간, 햄버거 만들기, 신고 결과 받기, 둘만의 암호
달리기 경주
link : https://school.programmers.co.kr/learn/courses/30/lessons/178871
문제 설명
얀에서는 매년 달리기 경주가 열립니다. 해설진들은 선수들이 자기 바로 앞의 선수를 추월할 때 추월한 선수의 이름을 부릅니다. 예를 들어 1등부터 3등까지 "mumu", "soe", "poe" 선수들이 순서대로 달리고 있을 때, 해설진이 "soe"선수를 불렀다면 2등인 "soe" 선수가 1등인 "mumu" 선수를 추월했다는 것입니다. 즉 "soe" 선수가 1등, "mumu" 선수가 2등으로 바뀝니다.
선수들의 이름이 1등부터 현재 등수 순서대로 담긴 문자열 배열 players와 해설진이 부른 이름을 담은 문자열 배열 callings가 매개변수로 주어질 때, 경주가 끝났을 때 선수들의 이름을 1등부터 등수 순서대로 배열에 담아 return 하는 solution 함수를 완성해주세요.
제한사항
- 5 ≤ players의 길이 ≤ 50,000
- players[i]는 i번째 선수의 이름을 의미합니다.
- players의 원소들은 알파벳 소문자로만 이루어져 있습니다.
- players에는 중복된 값이 들어가 있지 않습니다.
- 3 ≤ players[i]의 길이 ≤ 10
- 2 ≤ callings의 길이 ≤ 1,000,000
- callings는 players의 원소들로만 이루어져 있습니다.
- 경주 진행중 1등인 선수의 이름은 불리지 않습니다.
입출력 예
players callings result
| ["mumu", "soe", "poe", "kai", "mine"] | ["kai", "kai", "mine", "mine"] | ["mumu", "kai", "mine", "soe", "poe"] |
코드 제출 :
# 제출
def solution(players, callings):
ranks = {v:i for i, v in enumerate(players)}
for call in callings:
idx = ranks[call]
players[idx], players[idx-1] = players[idx-1], players[idx]
ranks[players[idx]], ranks[players[idx-1]] = ranks[players[idx-1]], ranks[players[idx]]
return players
해설
처음에 단순하게 아래처럼 도전하고 시간 초과 났음.
# 9, 10, 11, 12, 13 - 시간초과
def solution(players, callings):
for call in callings:
idx = players.index(call)
players[idx], players[idx-1] = players[idx-1], players[idx]
return players
index도 결국 loop 돌아서 가져오는 만큼 안되었던 것.. 그래서 dict에 정보 저장하고, players가 변경될 때 마다 dict에 저장한 정보도 갱신함.
점수 : 1434(+6)
추억 점수
link : https://school.programmers.co.kr/learn/courses/30/lessons/176963
문제 설명
사진들을 보며 추억에 젖어 있던 루는 사진별로 추억 점수를 매길려고 합니다. 사진 속에 나오는 인물의 그리움 점수를 모두 합산한 값이 해당 사진의 추억 점수가 됩니다. 예를 들어 사진 속 인물의 이름이 ["may", "kein", "kain"]이고 각 인물의 그리움 점수가 [5점, 10점, 1점]일 때 해당 사진의 추억 점수는 16(5 + 10 + 1)점이 됩니다. 다른 사진 속 인물의 이름이 ["kali", "mari", "don", "tony"]이고 ["kali", "mari", "don"]의 그리움 점수가 각각 [11점, 1점, 55점]]이고, "tony"는 그리움 점수가 없을 때, 이 사진의 추억 점수는 3명의 그리움 점수를 합한 67(11 + 1 + 55)점입니다.
그리워하는 사람의 이름을 담은 문자열 배열 name, 각 사람별 그리움 점수를 담은 정수 배열 yearning, 각 사진에 찍힌 인물의 이름을 담은 이차원 문자열 배열 photo가 매개변수로 주어질 때, 사진들의 추억 점수를 photo에 주어진 순서대로 배열에 담아 return하는 solution 함수를 완성해주세요.
제한사항
- 3 ≤ name의 길이 = yearning의 길이≤ 100
- 3 ≤ name의 원소의 길이 ≤ 7
- name의 원소들은 알파벳 소문자로만 이루어져 있습니다.
- name에는 중복된 값이 들어가지 않습니다.
- 1 ≤ yearning[i] ≤ 100
- yearning[i]는 i번째 사람의 그리움 점수입니다.
- 3 ≤ photo의 길이 ≤ 100
- 1 ≤ photo[i]의 길이 ≤ 100
- 3 ≤ photo[i]의 원소(문자열)의 길이 ≤ 7
- photo[i]의 원소들은 알파벳 소문자로만 이루어져 있습니다.
- photo[i]의 원소들은 중복된 값이 들어가지 않습니다.
입출력 예
| name | yearning | photo | result |
| ["may", "kein", "kain", "radi"] | [5, 10, 1, 3] | [["may", "kein", "kain", "radi"],["may", "kein", "brin", "deny"], ["kon", "kain", "may", "coni"]] | [19, 15, 6] |
| ["kali", "mari", "don"] | [11, 1, 55] | [["kali", "mari", "don"], ["pony", "tom", "teddy"], ["con", "mona", "don"]] | [67, 0, 55] |
| ["may", "kein", "kain", "radi"] | [5, 10, 1, 3] | [["may"],["kein", "deny", "may"], ["kon", "coni"]] | [5, 15, 0] |
코드 제출 :
# 제출
def solution(name, yearning, photo):
score = {n:y for n, y in zip(name, yearning)}
total = []
for value in photo:
total.append(sum([score[v] if v in score else 0 for v in value]))
return total
해설
이번에도 name과 yearning을 dict으로 만들고 sum 하면서 조건을 걸어서 처리.
점수 : 1435(+1)
대충 만든 자판
link : https://school.programmers.co.kr/learn/courses/30/lessons/160586
문제 설명
휴대폰의 자판은 컴퓨터 키보드 자판과는 다르게 하나의 키에 여러 개의 문자가 할당될 수 있습니다. 키 하나에 여러 문자가 할당된 경우, 동일한 키를 연속해서 빠르게 누르면 할당된 순서대로 문자가 바뀝니다.
예를 들어, 1번 키에 "A", "B", "C" 순서대로 문자가 할당되어 있다면 1번 키를 한 번 누르면 "A", 두 번 누르면 "B", 세 번 누르면 "C"가 되는 식입니다.
같은 규칙을 적용해 아무렇게나 만든 휴대폰 자판이 있습니다. 이 휴대폰 자판은 키의 개수가 1개부터 최대 100개까지 있을 수 있으며, 특정 키를 눌렀을 때 입력되는 문자들도 무작위로 배열되어 있습니다. 또, 같은 문자가 자판 전체에 여러 번 할당된 경우도 있고, 키 하나에 같은 문자가 여러 번 할당된 경우도 있습니다. 심지어 아예 할당되지 않은 경우도 있습니다. 따라서 몇몇 문자열은 작성할 수 없을 수도 있습니다.
이 휴대폰 자판을 이용해 특정 문자열을 작성할 때, 키를 최소 몇 번 눌러야 그 문자열을 작성할 수 있는지 알아보고자 합니다.
1번 키부터 차례대로 할당된 문자들이 순서대로 담긴 문자열배열 keymap과 입력하려는 문자열들이 담긴 문자열 배열 targets가 주어질 때, 각 문자열을 작성하기 위해 키를 최소 몇 번씩 눌러야 하는지 순서대로 배열에 담아 return 하는 solution 함수를 완성해 주세요.
단, 목표 문자열을 작성할 수 없을 때는 -1을 저장합니다.
제한사항
- 1 ≤ keymap의 길이 ≤ 100
- 1 ≤ keymap의 원소의 길이 ≤ 100
- keymap[i]는 i + 1번 키를 눌렀을 때 순서대로 바뀌는 문자를 의미합니다.
- 예를 들어 keymap[0] = "ABACD" 인 경우 1번 키를 한 번 누르면 A, 두 번 누르면 B, 세 번 누르면 A 가 됩니다.
- keymap의 원소의 길이는 서로 다를 수 있습니다.
- keymap의 원소는 알파벳 대문자로만 이루어져 있습니다.
- 1 ≤ targets의 길이 ≤ 100
- 1 ≤ targets의 원소의 길이 ≤ 100
- targets의 원소는 알파벳 대문자로만 이루어져 있습니다.
입출력 예
| keymap | targets | result |
| ["ABACD", "BCEFD"] | ["ABCD","AABB"] | [9, 4] |
| ["AA"] | ["B"] | [-1] |
| ["AGZ", "BSSS"] | ["ASA","BGZ"] | [4, 6] |
코드 제출 :
# 제출
def solution(keymap, targets):
answer = [0]*len(targets)
tmp = dict()
for key in keymap:
for i,v in enumerate(key):
tmp[v] = min(i+1, tmp.get(v,20000))
for idx, target in enumerate(targets):
for t in target:
if t not in tmp:
answer[idx] = -1
break
else:
answer[idx]+=tmp[t]
return answer
해설
처음에 문제에 대해 전혀 감을 못 잡다가 keymap의 문자열을 둘 다 쓰는 것이고 그 중에서 min한 값들에 대한 count로서 이해함. 그리고 처음에 list comprehension으로 이중으로 for loop을 해서 코드를 축약해보고 싶었는데 에러 났다가 get에 대한 헷갈리는 부분 다시 잡고 처리함. 도와주신 스터디원 덕분..
점수 : 1442(+3)
크레인 인형뽑기 게임
link : https://school.programmers.co.kr/learn/courses/30/lessons/64061
문제 설명
게임개발자인 "죠르디"는 크레인 인형뽑기 기계를 모바일 게임으로 만들려고 합니다."죠르디"는 게임의 재미를 높이기 위해 화면 구성과 규칙을 다음과 같이 게임 로직에 반영하려고 합니다.
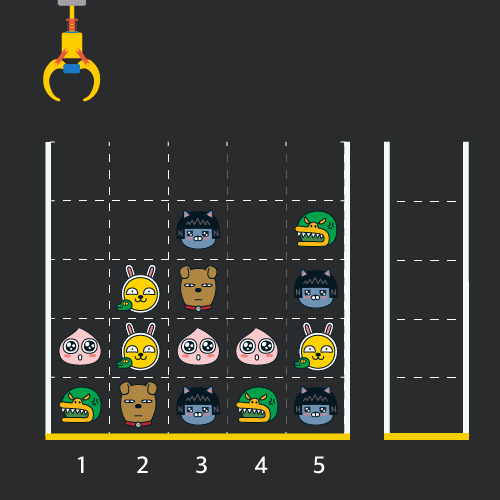
게임 화면은 "1 x 1" 크기의 칸들로 이루어진 "N x N" 크기의 정사각 격자이며 위쪽에는 크레인이 있고 오른쪽에는 바구니가 있습니다. (위 그림은 "5 x 5" 크기의 예시입니다). 각 격자 칸에는 다양한 인형이 들어 있으며 인형이 없는 칸은 빈칸입니다. 모든 인형은 "1 x 1" 크기의 격자 한 칸을 차지하며 격자의 가장 아래 칸부터 차곡차곡 쌓여 있습니다. 게임 사용자는 크레인을 좌우로 움직여서 멈춘 위치에서 가장 위에 있는 인형을 집어 올릴 수 있습니다. 집어 올린 인형은 바구니에 쌓이게 되는 데, 이때 바구니의 가장 아래 칸부터 인형이 순서대로 쌓이게 됩니다. 다음 그림은 [1번, 5번, 3번] 위치에서 순서대로 인형을 집어 올려 바구니에 담은 모습입니다.
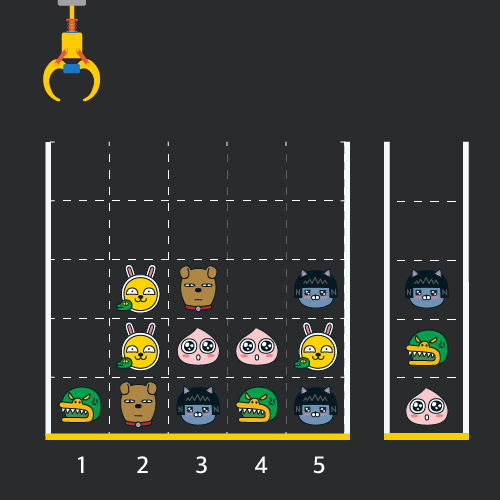
만약 같은 모양의 인형 두 개가 바구니에 연속해서 쌓이게 되면 두 인형은 터뜨려지면서 바구니에서 사라지게 됩니다. 위 상태에서 이어서 [5번] 위치에서 인형을 집어 바구니에 쌓으면 같은 모양 인형 두 개가 없어집니다.
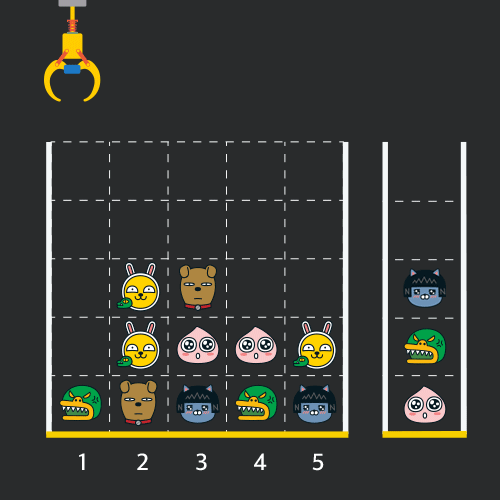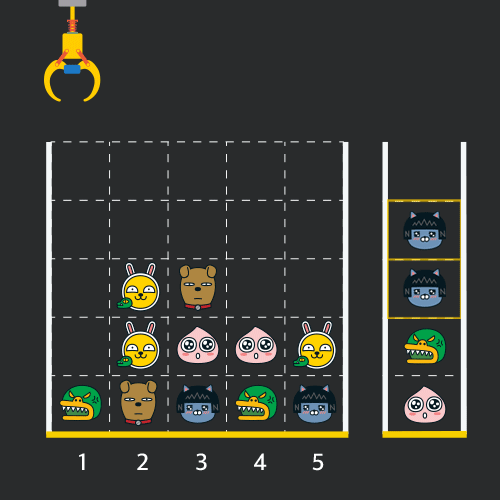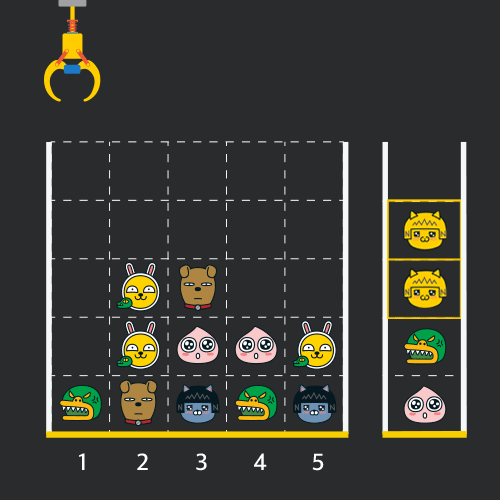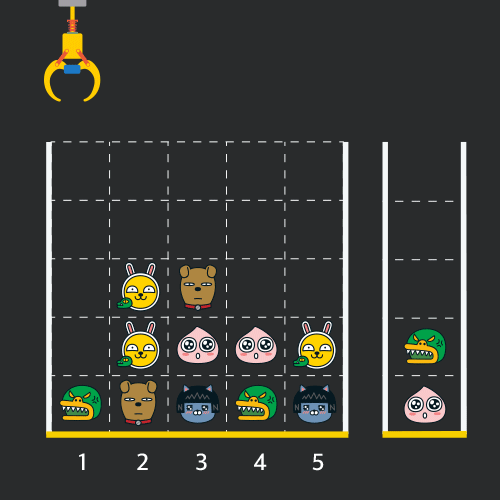
크레인 작동 시 인형이 집어지지 않는 경우는 없으나 만약 인형이 없는 곳에서 크레인을 작동시키는 경우에는 아무런 일도 일어나지 않습니다. 또한 바구니는 모든 인형이 들어갈 수 있을 만큼 충분히 크다고 가정합니다. (그림에서는 화면표시 제약으로 5칸만으로 표현하였음)
게임 화면의 격자의 상태가 담긴 2차원 배열 board와 인형을 집기 위해 크레인을 작동시킨 위치가 담긴 배열 moves가 매개변수로 주어질 때, 크레인을 모두 작동시킨 후 터트려져 사라진 인형의 개수를 return 하도록 solution 함수를 완성해주세요.
제한사항
- board 배열은 2차원 배열로 크기는 "5 x 5" 이상 "30 x 30" 이하입니다.
- board의 각 칸에는 0 이상 100 이하인 정수가 담겨있습니다.
- 0은 빈 칸을 나타냅니다.
- 1 ~ 100의 각 숫자는 각기 다른 인형의 모양을 의미하며 같은 숫자는 같은 모양의 인형을 나타냅니다.
- moves 배열의 크기는 1 이상 1,000 이하입니다.
- moves 배열 각 원소들의 값은 1 이상이며 board 배열의 가로 크기 이하인 자연수입니다.
입출력 예
| board | moves | result |
| [[0,0,0,0,0],[0,0,1,0,3],[0,2,5,0,1],[4,2,4,4,2],[3,5,1,3,1]] | [1,5,3,5,1,2,1,4] | 4 |
코드 제출 :
# 제출
def solution(board, moves):
basket = []
boards = [list(x) for x in zip(*board)] # 전치
board_size = len(board)
result = 0
for m in moves:
if sum(boards[m-1]) > 0:
for i in range(board_size):
if boards[m-1][i] != 0:
basket.append(boards[m-1][i])
boards[m-1][i] = 0
break
if len(basket) >= 2:
if basket[-1] == basket[-2]:
result += 2
basket.pop(-1)
basket.pop(-1)
return result
해설
처음에는 if len(basket) >= 2 부분을 for i in range(board_size) loop 안에 넣은 걸 생각 못하고 돌렸더니 2,8번에서 실패해서 다른 사람 질문에 js인데 나랑 구조가 비슷한 사람의 댓글에 if len(basket) >= 2 이 부분이 이중 for loop에서 같이 돌면서 에러나는 거라고 해서 빼니까 성공함.
실질적으로 이중 리스트를 전치한 다음에 m-1 의 인덱스 별 boards 로 접근한 다음에 조건에 맞으면 basket에 넣고 뺀 건 0으로 치환하고, basket에서 중복된 애들은 move 한 번당 count되는 셈이라 m 한 번당 증가인 셈이라서 m 한 번에 돌 때, 추가된 애랑 가장 앞에 애랑 비교해서 맞으면 pop 2번 하고 result 에서 +2 함.
점수 : 1438(+3)
문자열 나누기
link : https://school.programmers.co.kr/learn/courses/30/lessons/140108
문제 설명
문자열 s가 입력되었을 때 다음 규칙을 따라서 이 문자열을 여러 문자열로 분해하려고 합니다.
- 먼저 첫 글자를 읽습니다. 이 글자를 x라고 합시다.
- 이제 이 문자열을 왼쪽에서 오른쪽으로 읽어나가면서, x와 x가 아닌 다른 글자들이 나온 횟수를 각각 셉니다. 처음으로 두 횟수가 같아지는 순간 멈추고, 지금까지 읽은 문자열을 분리합니다.
- s에서 분리한 문자열을 빼고 남은 부분에 대해서 이 과정을 반복합니다. 남은 부분이 없다면 종료합니다.
- 만약 두 횟수가 다른 상태에서 더 이상 읽을 글자가 없다면, 역시 지금까지 읽은 문자열을 분리하고, 종료합니다.
문자열 s가 매개변수로 주어질 때, 위 과정과 같이 문자열들로 분해하고, 분해한 문자열의 개수를 return 하는 함수 solution을 완성하세요.
제한사항
- 1 ≤ s의 길이 ≤ 10,000
- s는 영어 소문자로만 이루어져 있습니다.
입출력 예
| s | result |
| "banana" | 3 |
| "abracadabra" | 6 |
| "aaabbaccccabba" | 3 |
코드 제출 :
# 제출
def solution(txt):
tmp, result = 0,0
for x in txt:
if tmp == 0:
result += 1
target = x
tmp += 1 if target == x else -1
return result
해설
같이 풀 때 문제 이해한 줄 알았는데 else를 넣고 왜 자꾸 틀리지 해서 스탑하고 다시 처음부터 풀면서 보니까 else를 넣으면 당연히 안 됨.. else를 넣으면 처음에 target = x 를 넣은 게 고정이 되어서 0이 되니까 글자수 그대로 카운트 됨.
점수 : 1443(+1)
신규 아이디 추천
link : https://school.programmers.co.kr/learn/courses/30/lessons/72410
문제 설명
카카오에 입사한 신입 개발자 네오는 "카카오계정개발팀"에 배치되어, 카카오 서비스에 가입하는 유저들의 아이디를 생성하는 업무를 담당하게 되었습니다. "네오"에게 주어진 첫 업무는 새로 가입하는 유저들이 카카오 아이디 규칙에 맞지 않는 아이디를 입력했을 때, 입력된 아이디와 유사하면서 규칙에 맞는 아이디를 추천해주는 프로그램을 개발하는 것입니다.다음은 카카오 아이디의 규칙입니다.
- 아이디의 길이는 3자 이상 15자 이하여야 합니다.
- 아이디는 알파벳 소문자, 숫자, 빼기(``), 밑줄(_), 마침표(.) 문자만 사용할 수 있습니다.
- 단, 마침표(.)는 처음과 끝에 사용할 수 없으며 또한 연속으로 사용할 수 없습니다.
"네오"는 다음과 같이 7단계의 순차적인 처리 과정을 통해 신규 유저가 입력한 아이디가 카카오 아이디 규칙에 맞는 지 검사하고 규칙에 맞지 않은 경우 규칙에 맞는 새로운 아이디를 추천해 주려고 합니다.신규 유저가 입력한 아이디가 new_id 라고 한다면,
1단계 new_id의 모든 대문자를 대응되는 소문자로 치환합니다.
2단계 new_id에서 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.)를 제외한 모든 문자를 제거합니다.
3단계 new_id에서 마침표(.)가 2번 이상 연속된 부분을 하나의 마침표(.)로 치환합니다.
4단계 new_id에서 마침표(.)가 처음이나 끝에 위치한다면 제거합니다.
5단계 new_id가 빈 문자열이라면, new_id에 "a"를 대입합니다.
6단계 new_id의 길이가 16자 이상이면, new_id의 첫 15개의 문자를 제외한 나머지 문자들을 모두 제거합니다. 만약 제거 후 마침표(.)가 new_id의 끝에 위치한다면 끝에 위치한 마침표(.) 문자를 제거합니다.
7단계 new_id의 길이가 2자 이하라면, new_id의 마지막 문자를 new_id의 길이가 3이 될 때까지 반복해서 끝에 붙입니다.
예를 들어, new_id 값이 "...!@BaT#*..y.abcdefghijklm" 라면, 위 7단계를 거치고 나면 new_id는 아래와 같이 변경됩니다.
1단계 대문자 'B'와 'T'가 소문자 'b'와 't'로 바뀌었습니다."...!@BaT#*..y.abcdefghijklm" → "...!@bat#*..y.abcdefghijklm"
2단계 '!', '@', '#', '*' 문자가 제거되었습니다."...!@bat#*..y.abcdefghijklm" → "...bat..y.abcdefghijklm"
3단계 '...'와 '..' 가 '.'로 바뀌었습니다."...bat..y.abcdefghijklm" → ".bat.y.abcdefghijklm"
4단계 아이디의 처음에 위치한 '.'가 제거되었습니다.".bat.y.abcdefghijklm" → "bat.y.abcdefghijklm"
5단계 아이디가 빈 문자열이 아니므로 변화가 없습니다."bat.y.abcdefghijklm" → "bat.y.abcdefghijklm"
6단계 아이디의 길이가 16자 이상이므로, 처음 15자를 제외한 나머지 문자들이 제거되었습니다."bat.y.abcdefghijklm" → "bat.y.abcdefghi"
7단계 아이디의 길이가 2자 이하가 아니므로 변화가 없습니다."bat.y.abcdefghi" → "bat.y.abcdefghi"
따라서 신규 유저가 입력한 new_id가 "...!@BaT#*..y.abcdefghijklm"일 때, 네오의 프로그램이 추천하는 새로운 아이디는 "bat.y.abcdefghi" 입니다.
[문제]
신규 유저가 입력한 아이디를 나타내는 new_id가 매개변수로 주어질 때, "네오"가 설계한 7단계의 처리 과정을 거친 후의 추천 아이디를 return 하도록 solution 함수를 완성해 주세요.
[제한사항]
new_id는 길이 1 이상 1,000 이하인 문자열입니다.new_id는 알파벳 대문자, 알파벳 소문자, 숫자, 특수문자로 구성되어 있습니다.new_id에 나타날 수 있는 특수문자는 -_.~!@#$%^&*()=+[{]}:?,<>/ 로 한정됩니다.
[입출력 예]
| no | new_id | result |
| 예1 | "...!@BaT#*..y.abcdefghijklm" | "bat.y.abcdefghi" |
| 예2 | "z-+.^." | "z--" |
| 예3 | "=.=" | "aaa" |
| 예4 | "123_.def" | "123_.def" |
| 예5 | "abcdefghijklmn.p" | "abcdefghijklmn" |
코드 제출 :
# 제출
import re
def solution(new_id):
exc = r'[\~\!\@\#\$\%\^\&\*\(\)\=\+\[\{\]\}\:\?\,\<\>\/]'
new_id = new_id.lower()
new_id = re.sub(exc, '', new_id)
new_id = re.sub(r'\.{2,}', '.', new_id)
if new_id[0] == '.':
new_id = new_id[1:]
if len(new_id) > 0:
if new_id[-1] == '.':
new_id = new_id[:-1]
if len(new_id) == 0:
new_id = 'a'
if len(new_id) >= 16:
new_id = new_id[:15]
if new_id[-1] == '.':
new_id = new_id[:-1]
if len(new_id) <= 2:
while len(new_id) < 3:
new_id = new_id+(new_id[-1])
return new_id
해설
정규식을 이용. 말 그대로 단계별로 쭉 이어짐.
1단계 new_id의 모든 대문자를 대응되는 소문자로 치환합니다.
-> 소문자는 lower()를 이용
2단계 new_id에서 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.)를 제외한 모든 문자를 제거합니다.
-> exc = r'[\\~\\!\\@\\#\\$\\%\\^\\&\\*\\(\\)\\=\\+\\[\\{\\]\\}\\:\\?\\,\\<\\>\\/]' 와 new_id = re.sub(exc, '', new_id) 로 처리
3단계 new_id에서 마침표(.)가 2번 이상 연속된 부분을 하나의 마침표(.)로 치환합니다.
-> re.sub(r'\\.{2,}', '.', new_id) 로 처리
4단계 new_id에서 마침표(.)가 처음이나 끝에 위치한다면 제거합니다.
-> new_id[0] == '.' 와 new_id[-1] == '.'로 처리하되, new_id[0] == '.' 처리 후 빈 문자열인 경우 고려함.
5단계 new_id가 빈 문자열이라면, new_id에 "a"를 대입합니다.
-> len(new_id) == 0 시 new_id = 'a' 처리.
6단계 new_id의 길이가 16자 이상이면, new_id의 첫 15개의 문자를 제외한 나머지 문자들을 모두 제거합니다.
만약 제거 후 마침표(.)가 new_id의 끝에 위치한다면 끝에 위치한 마침표(.) 문자를 제거합니다.
-> new_id = new_id[:15] 로 자르고 자른 뒤에 맨 마지막이 .이면 new_id = new_id[:-1] 처리.
7단계 new_id의 길이가 2자 이하라면, new_id의 마지막 문자를 new_id의 길이가 3이 될 때까지 반복해서 끝에 붙입니다.
-> while len(new_id) < 3로 처리.
다만 나보다 좀 더 깔끔하게? 혹은 짧게 하신 분을 보고 이런 식으로 축약하는 것도 고려해야 겠다 배움.
mport re
def solution(new_id):
st = new_id
st = st.lower()
st = re.sub('[^a-z0-9\\-_.]', '', st) # 알파벳, 숫가, -,_,. 제외하고 ''로 바꾼 문자열 반환환
st = re.sub('\\.+', '.', st) # .이 1개 이상이면 .으로만 환
st = re.sub('^[.]|[.]$', '', st) # 시작 or 끝이 .이면 ''로 바꾼 문자열 반환환
st = 'a' if len(st) == 0 else st[:15] # 길이가 0이면 a 그 이상이면 15자까지 자르는 것을 하나로 합쳐짐.
st = re.sub('^[.]|[.]$', '', st)
st = st if len(st) > 2 else st + "".join([st[-1] for i in range(3-len(st))]) # 길이가 3 이상이면 그대로 미만일 때 3에서 자른 값들로서 join 처리
return st
점수 : 1439(+1)
성격 유형 검사하기
link : https://school.programmers.co.kr/learn/courses/30/lessons/118666
문제 설명
나만의 카카오 성격 유형 검사지를 만들려고 합니다.성격 유형 검사는 다음과 같은 4개 지표로 성격 유형을 구분합니다. 성격은 각 지표에서 두 유형 중 하나로 결정됩니다.
| 지표 번호 | 성격 유형 |
| 1번 지표 | 라이언형(R), 튜브형(T) |
| 2번 지표 | 콘형(C), 프로도형(F) |
| 3번 지표 | 제이지형(J), 무지형(M) |
| 4번 지표 | 어피치형(A), 네오형(N) |
4개의 지표가 있으므로 성격 유형은 총 16(=2 x 2 x 2 x 2)가지가 나올 수 있습니다. 예를 들어, "RFMN"이나 "TCMA"와 같은 성격 유형이 있습니다.
검사지에는 총 n개의 질문이 있고, 각 질문에는 아래와 같은 7개의 선택지가 있습니다.
- 매우 비동의
- 비동의
- 약간 비동의
- 모르겠음
- 약간 동의
- 동의
- 매우 동의
각 질문은 1가지 지표로 성격 유형 점수를 판단합니다.
예를 들어, 어떤 한 질문에서 4번 지표로 아래 표처럼 점수를 매길 수 있습니다.
| 선택지 성격 | 유형 점수 |
| 매우 비동의 | 네오형 3점 |
| 비동의 | 네오형 2점 |
| 약간 비동의 | 네오형 1점 |
| 모르겠음 | 어떤 성격 유형도 점수를 얻지 않습니다 |
| 약간 동의 | 어피치형 1점 |
| 동의 | 어피치형 2점 |
| 매우 동의 | 어피치형 3점 |
이때 검사자가 질문에서 약간 동의 선택지를 선택할 경우 어피치형(A) 성격 유형 1점을 받게 됩니다. 만약 검사자가 매우 비동의 선택지를 선택할 경우 네오형(N) 성격 유형 3점을 받게 됩니다.
**위 예시처럼 네오형이 비동의, 어피치형이 동의인 경우만 주어지지 않고, 질문에 따라 네오형이 동의, 어피치형이 비동의인 경우도 주어질 수 있습니다.**하지만 각 선택지는 고정적인 크기의 점수를 가지고 있습니다.
- 매우 동의나 매우 비동의 선택지를 선택하면 3점을 얻습니다.
- 동의나 비동의 선택지를 선택하면 2점을 얻습니다.
- 약간 동의나 약간 비동의 선택지를 선택하면 1점을 얻습니다.
- 모르겠음 선택지를 선택하면 점수를 얻지 않습니다.
검사 결과는 모든 질문의 성격 유형 점수를 더하여 각 지표에서 더 높은 점수를 받은 성격 유형이 검사자의 성격 유형이라고 판단합니다. 단, 하나의 지표에서 각 성격 유형 점수가 같으면, 두 성격 유형 중 사전 순으로 빠른 성격 유형을 검사자의 성격 유형이라고 판단합니다.
질문마다 판단하는 지표를 담은 1차원 문자열 배열 survey와 검사자가 각 질문마다 선택한 선택지를 담은 1차원 정수 배열 choices가 매개변수로 주어집니다. 이때, 검사자의 성격 유형 검사 결과를 지표 번호 순서대로 return 하도록 solution 함수를 완성해주세요.
제한사항
- 1 ≤ survey의 길이 ( = n) ≤ 1,000
- survey의 원소는 "RT", "TR", "FC", "CF", "MJ", "JM", "AN", "NA" 중 하나입니다.
- survey[i]의 첫 번째 캐릭터는 i+1번 질문의 비동의 관련 선택지를 선택하면 받는 성격 유형을 의미합니다.
- survey[i]의 두 번째 캐릭터는 i+1번 질문의 동의 관련 선택지를 선택하면 받는 성격 유형을 의미합니다.
- choices의 길이 = survey의 길이
- choices[i]는 검사자가 선택한 i+1번째 질문의 선택지를 의미합니다.
- 1 ≤ choices의 원소 ≤ 7
choices 뜻 1 매우 비동의 2 비동의 3 약간 비동의 4 모르겠음 5 약간 동의 6 동의 7 매우 동의
입출력 예
| survey | choices | result |
| ["AN", "CF", "MJ", "RT", "NA"] | [5, 3, 2, 7, 5] | "TCMA" |
| ["TR", "RT", "TR"] | [7, 1, 3] | "RCJA" |
코드 제출 :
# 제출
def solution(survey, choices):
answer = ''
select = [-3, -2, -1, 0, 1, 2, 3]
metrics = {'R': 0, 'T': 0, 'C':0, 'F':0, 'J':0, 'M':0, 'A':0, 'N':0}
for character, num in zip(survey, choices):
score = select[num-1]
first, second = character[0], character[1]
if score > 0:
metrics[second] += score
elif score < 0:
metrics[first] += -score
for i in ['RT', 'CF', 'JM', 'AN']:
first,second = i[0], i[1]
answer += second if metrics[first] < metrics[second] else first
return answer
해설
같이 풀면서 해 봄. 처음에 문제를 이해 못하다가 select = [-3, -2, -1, 0, 1, 2, 3] 이런 식으로 선택에 대해 매우 비동의~매우 동의를 처리한 후에, 유형별을 dict으로 만들고나서 조사와 선택을 zip으로 같이 돌리면서 진행함. 성격 유형을 first, second로 나눈 뒤에 점수에 따라서 유형을 처리하면서 음수로 한 것도 -를 다시 붙여서 양수화 한 다음에 += 처리 해서 카운트 함. 그러고 나서 다시 지표 번호에 따라서 for loop을 돌리면서 처리해서 answer로 처리.
점수 : 1444(+1)
개인정보 수집 유효기간
link : https://school.programmers.co.kr/learn/courses/30/lessons/150370
문제 설명
고객의 약관 동의를 얻어서 수집된 1~n번으로 분류되는 개인정보 n개가 있습니다. 약관 종류는 여러 가지 있으며 각 약관마다 개인정보 보관 유효기간이 정해져 있습니다. 당신은 각 개인정보가 어떤 약관으로 수집됐는지 알고 있습니다. 수집된 개인정보는 유효기간 전까지만 보관 가능하며, 유효기간이 지났다면 반드시 파기해야 합니다.
예를 들어, A라는 약관의 유효기간이 12 달이고, 2021년 1월 5일에 수집된 개인정보가 A약관으로 수집되었다면 해당 개인정보는 2022년 1월 4일까지 보관 가능하며 2022년 1월 5일부터 파기해야 할 개인정보입니다.당신은 오늘 날짜로 파기해야 할 개인정보 번호들을 구하려 합니다.
모든 달은 28일까지 있다고 가정합니다.
다음은 오늘 날짜가 2022.05.19일 때의 예시입니다.
| 약관 종류 | 유효기간 |
| A | 6 달 |
| B | 12 달 |
| C | 3 달 |
| 번호 | 개인정보 수집 일자 | 약관 종류 |
| 1 | 2021.05.02 | A |
| 2 | 2021.07.01 | B |
| 3 | 2022.02.19 | C |
| 4 | 2022.02.20 | C |
- 첫 번째 개인정보는 A약관에 의해 2021년 11월 1일까지 보관 가능하며, 유효기간이 지났으므로 파기해야 할 개인정보입니다.
- 두 번째 개인정보는 B약관에 의해 2022년 6월 28일까지 보관 가능하며, 유효기간이 지나지 않았으므로 아직 보관 가능합니다.
- 세 번째 개인정보는 C약관에 의해 2022년 5월 18일까지 보관 가능하며, 유효기간이 지났으므로 파기해야 할 개인정보입니다.
- 네 번째 개인정보는 C약관에 의해 2022년 5월 19일까지 보관 가능하며, 유효기간이 지나지 않았으므로 아직 보관 가능합니다.
따라서 파기해야 할 개인정보 번호는 [1, 3]입니다.
오늘 날짜를 의미하는 문자열 today, 약관의 유효기간을 담은 1차원 문자열 배열 terms와 수집된 개인정보의 정보를 담은 1차원 문자열 배열 privacies가 매개변수로 주어집니다. 이때 파기해야 할 개인정보의 번호를 오름차순으로 1차원 정수 배열에 담아 return 하도록 solution 함수를 완성해 주세요.
입출력 예
| today | terms | privacies | result |
| "2022.05.19" | ["A 6", "B 12", "C 3"] | ["2021.05.02 A", "2021.07.01 B", "2022.02.19 C", "2022.02.20 C"] | [1, 3] |
| "2020.01.01" | ["Z 3", "D 5"] | ["2019.01.01 D", "2019.11.15 Z", "2019.08.02 D", "2019.07.01 D", "2018.12.28 Z"] | [1, 4, 5] |
코드 제출 :
# 제출
def solution(today, terms, privacies):
answer = []
year,month,day = map(int,today.split('.'))
terms_dic = {term.split(' ')[0] : int(term.split(' ')[1])*28 for term in terms}
today = int(year)*12*28 + int(month)*28 + int(day)
for idx, val in enumerate(privacies):
date, case = val.split(' ')
AfterYY, AfterMM, AfterDD = int(date.split('.')[0]),int(date.split('.')[1]),int(date.split('.')[2])
AfterDate = (AfterYY*12*28)+(AfterMM*28) + AfterDD
if AfterDate+(terms_dic[case]) <= today:
answer.append(idx+1)
return answer
해설
처음에 실패한 코드:
# 테스트 실패 6 ~ 19
def solution(today, terms, privacies):
answer = []
year, month, day = int(today.split('.')[0]), int(today.split('.')[1]), int(today.split('.')[2])
term_dict = {term.split()[0]:int(term.split()[1]) for term in terms}
for i in range(len(privacies)):
date, term = privacies[i].split()
caseYY, caseMM, caseDD = int(date.split('.')[0]), int(date.split('.')[1]), int(date.split('.')[2])
AfterMM, AfterYY = 0, caseYY
if (caseMM+term_dict[term]) // 12 > 0:
AfterMM = (caseMM+term_dict[term]) % 12
AfterYY += 1
else:
AfterMM = (caseMM+term_dict[term])
if AfterYY < year:
answer.append(1+i)
elif AfterYY == year:
if AfterMM < month:
answer.append(1+i)
elif AfterMM == month:
if caseDD <= day:
answer.append(1+i)
return answer
today, terms, privacies, result = "2022.05.19", ["A 6", "B 12", "C 3"], ["2021.05.02 A", "2021.07.01 B", "2022.02.19 C", "2022.02.20 C"], [1, 3]
today, terms, privacies, result = "2020.01.01", ["Z 3", "D 5"], ["2019.01.01 D", "2019.11.15 Z", "2019.08.02 D", "2019.07.01 D", "2018.12.28 Z"], [1, 4, 5]
solution(today, terms, privacies)논리상으로 될 거라고 생각했는데 광탈함..ㅋㅋㅋㅋ
그러고 나서 질문 보다가 year,month,day = map(int,today.split('.')) 를 map 처리한 걸 배워서 하다가 28일로 고정이니 그걸로 계산을 한꺼번에 한 걸 봤는데 난 그렇게는 못하고 그냥 무식하게 *28 해서 맞추고나니까 그 다음부터는 오히려 조건이 줄어서 쉬웠음… 월, 년 신경 안 써도 되서..ㅋㅋ쿠ㅜ
점수 : 1446(+2)
햄버거 만들기
link : https://school.programmers.co.kr/learn/courses/30/lessons/133502
문제 설명
햄버거 가게에서 일을 하는 상수는 햄버거를 포장하는 일을 합니다. 함께 일을 하는 다른 직원들이 햄버거에 들어갈 재료를 조리해 주면 조리된 순서대로 상수의 앞에 아래서부터 위로 쌓이게 되고, 상수는 순서에 맞게 쌓여서 완성된 햄버거를 따로 옮겨 포장을 하게 됩니다. 상수가 일하는 가게는 정해진 순서(아래서부터, 빵 – 야채 – 고기 - 빵)로 쌓인 햄버거만 포장을 합니다. 상수는 손이 굉장히 빠르기 때문에 상수가 포장하는 동안 속 재료가 추가적으로 들어오는 일은 없으며, 재료의 높이는 무시하여 재료가 높이 쌓여서 일이 힘들어지는 경우는 없습니다.
예를 들어, 상수의 앞에 쌓이는 재료의 순서가 [야채, 빵, 빵, 야채, 고기, 빵, 야채, 고기, 빵]일 때, 상수는 여섯 번째 재료가 쌓였을 때, 세 번째 재료부터 여섯 번째 재료를 이용하여 햄버거를 포장하고, 아홉 번째 재료가 쌓였을 때, 두 번째 재료와 일곱 번째 재료부터 아홉 번째 재료를 이용하여 햄버거를 포장합니다. 즉, 2개의 햄버거를 포장하게 됩니다.
상수에게 전해지는 재료의 정보를 나타내는 정수 배열 ingredient가 주어졌을 때, 상수가 포장하는 햄버거의 개수를 return 하도록 solution 함수를 완성하시오.
제한사항
- 1 ≤ ingredient의 길이 ≤ 1,000,000
- ingredient의 원소는 1, 2, 3 중 하나의 값이며, 순서대로 빵, 야채, 고기를 의미합니다.
입출력 예
| ingredient | result |
| [2, 1, 1, 2, 3, 1, 2, 3, 1] | 2 |
| [1, 3, 2, 1, 2, 1, 3, 1, 2] | 0 |
코드 제출 :
# 제출
def solution(ingredient):
answer = 0
idx = 0
while idx < len(ingredient)-3 :
if ingredient[idx] == 1:
if ingredient[idx:idx+4] == [1,2,3,1]:
answer += 1
del ingredient[idx:idx+4]
idx -= 3
continue
idx += 1
return answer
해설
처음엔 tmp_list 같은 걸 만들어서 while로 돌리면서 넣었다가 뺐다가 했더니 런타임 에러 전에 우선 틀렸다고 나와서 그냥 억지로 하지 말고 다른 방법 찾다가 질문에서 그냥 del을 이용한 방법을 보고 응용함. idx는 0부터 시작해서 slicing으로 잘라내고 4개까지 자른 게 [1,2,3,1]이면 그걸 del 하고 정답에 +1 하고 인덱스는 -3 해서 앞으로 당기게 해서 초기화 하고 계속 진행되도록 continue 처리 하고, 조건에 안 맞으면 인덱스 +1 추가 해서 계속 돌아가게 하다가 인덱스가 햄버거 1개를 환성하는 idx인 4개 미만이면 stop하도록 처리.
점수 : 1451(+5)
신고 결과 받기
link : https://school.programmers.co.kr/learn/courses/30/lessons/92334
문제 설명
신입사원 무지는 게시판 불량 이용자를 신고하고 처리 결과를 메일로 발송하는 시스템을 개발하려 합니다. 무지가 개발하려는 시스템은 다음과 같습니다.
- 각 유저는 한 번에 한 명의 유저를 신고할 수 있습니다.
- 신고 횟수에 제한은 없습니다. 서로 다른 유저를 계속해서 신고할 수 있습니다.
- 한 유저를 여러 번 신고할 수도 있지만, 동일한 유저에 대한 신고 횟수는 1회로 처리됩니다.
- k번 이상 신고된 유저는 게시판 이용이 정지되며, 해당 유저를 신고한 모든 유저에게 정지 사실을 메일로 발송합니다.
- 유저가 신고한 모든 내용을 취합하여 마지막에 한꺼번에 게시판 이용 정지를 시키면서 정지 메일을 발송합니다.
다음은 전체 유저 목록이 ["muzi", "frodo", "apeach", "neo"]이고, k = 2(즉, 2번 이상 신고당하면 이용 정지)인 경우의 예시입니다.
| 유저 ID | 유저가 신고한 ID | 설명 |
| "muzi" | "frodo" | "muzi"가 "frodo"를 신고했습니다. |
| "apeach" | "frodo" | "apeach"가 "frodo"를 신고했습니다. |
| "frodo" | "neo" | "frodo"가 "neo"를 신고했습니다. |
| "muzi" | "neo" | "muzi"가 "neo"를 신고했습니다. |
| "apeach" | "muzi" | "apeach"가 "muzi"를 신고했습니다. |
각 유저별로 신고당한 횟수는 다음과 같습니다.
| 유저 ID | 신고당한 횟수 |
| "muzi" | 1 |
| "frodo" | 2 |
| "apeach" | 0 |
| "neo" | 2 |
위 예시에서는 2번 이상 신고당한 "frodo"와 "neo"의 게시판 이용이 정지됩니다. 이때, 각 유저별로 신고한 아이디와 정지된 아이디를 정리하면 다음과 같습니다.
| 유저 ID | 유저가 신고한 ID | 정지된 ID |
| "muzi" | ["frodo", "neo"] | ["frodo", "neo"] |
| "frodo" | ["neo"] | ["neo"] |
| "apeach" | ["muzi", "frodo"] | ["frodo"] |
| "neo" | 없음 | 없음 |
따라서 "muzi"는 처리 결과 메일을 2회, "frodo"와 "apeach"는 각각 처리 결과 메일을 1회 받게 됩니다.
이용자의 ID가 담긴 문자열 배열 id_list, 각 이용자가 신고한 이용자의 ID 정보가 담긴 문자열 배열 report, 정지 기준이 되는 신고 횟수 k가 매개변수로 주어질 때, 각 유저별로 처리 결과 메일을 받은 횟수를 배열에 담아 return 하도록 solution 함수를 완성해주세요.
입출력 예
| id_list | report | k | result |
| ["muzi", "frodo", "apeach", "neo"] | ["muzi frodo","apeach frodo","frodo neo","muzi neo","apeach muzi"] | 2 | [2,1,1,0] |
| ["con", "ryan"] | ["ryan con", "ryan con", "ryan con", "ryan con"] | 3 | [0,0] |
코드 제출 :
# 제출
def solution(id_list, report, k):
answer = {k:list() for k in id_list}
reported = {x: 0 for x in id_list}
for r in set(report):
ask_id,reported_id = r.split()
reported[reported_id] += 1
answer[ask_id].append(reported_id)
for user, re in answer.items():
answer[user] = sum(1 for u in re if reported[u] >= k)
return list(answer.values())
해설
우선 설명을 따랐다. answer에 신고자 : [신고한 아이디]를 dict으로 넣고 id_list에서도 신고당한 걸 count 하려고 id:0으로 dict을 만듬. 그러고 나서 report를 set으로 감싸서 중복을 줄이고 신고자, 신고당한 사용자로 나누고 그걸 reported에서 +1 로 카운트를 하면서 answer에 신고자가 신고 당한 사용자를 list 넣어서 저장함. 그러고 나서 answer에서 for loop으로 확인하면서 k수 이상이면 1로 해서 블록당한 사용자를 카운트 하게 한 후에 value들만 list화 함.
점수 : 1452(+1)
둘만의 암호
link : https://school.programmers.co.kr/learn/courses/30/lessons/155652
문제 설명
두 문자열 s와 skip, 그리고 자연수 index가 주어질 때, 다음 규칙에 따라 문자열을 만들려 합니다. 암호의 규칙은 다음과 같습니다.
- 문자열 s의 각 알파벳을 index만큼 뒤의 알파벳으로 바꿔줍니다.
- index만큼의 뒤의 알파벳이 z를 넘어갈 경우 다시 a로 돌아갑니다.
- skip에 있는 알파벳은 제외하고 건너뜁니다.
예를 들어 s = "aukks", skip = "wbqd", index = 5일 때, a에서 5만큼 뒤에 있는 알파벳은 f지만 [b, c, d, e, f]에서 'b'와 'd'는 skip에 포함되므로 세지 않습니다. 따라서 'b', 'd'를 제외하고 'a'에서 5만큼 뒤에 있는 알파벳은 [c, e, f, g, h] 순서에 의해 'h'가 됩니다. 나머지 "ukks" 또한 위 규칙대로 바꾸면 "appy"가 되며 결과는 "happy"가 됩니다.
두 문자열 s와 skip, 그리고 자연수 index가 매개변수로 주어질 때 위 규칙대로 s를 변환한 결과를 return하도록 solution 함수를 완성해주세요.
제한사항
- 5 ≤ s의 길이 ≤ 50
- 1 ≤ skip의 길이 ≤ 10
- s와 skip은 알파벳 소문자로만 이루어져 있습니다.
- skip에 포함되는 알파벳은 s에 포함되지 않습니다.
- 1 ≤ index ≤ 20
입출력 예
| s | skip | index | result |
| "aukks" | "wbqd" | 5 | "happy" |
코드 제출 :
# 제출
def solution(s, skip, index):
answer = ''
alpha = [chr(txt) for txt in range(97, 123) if chr(txt) not in skip]
for i in s:
tmp = alpha.index(i) + index
tmp %= len(alpha)
answer += alpha[tmp]
return answer
해설
알려준 대로 해서 나중에 혼자 해봐야 할 듯.ㅠㅠ 그래도 방법론적으로 처음에 skip에 있는 걸 제외하는 방법을 생각하지 못하고 있는 것 안에서 while로 하는 방식은 비효율적인 것으로 판명.
점수 : 1461(+3)
마지막 둘 만의 암호까지 끝!
'스터디 > Python' 카테고리의 다른 글
| [CodingTest][2023-05-02]프로그래머스 코딩테스트 Lv.2 문제들 (0) | 2023.05.02 |
|---|---|
| [CodingTest][2023-02-14~]프로그래머스 코딩테스트 Lv.1 문제들 (1) | 2023.04.10 |
| [CodingTest][2023-01-20~26]프로그래머스 코딩테스트 Lv.1 문제들 (0) | 2023.02.14 |
| [CodingTest][2023-01-13~01-20]프로그래머스 코딩테스트 Lv.1 (1) | 2023.01.20 |
| [CodingTest][2023-01-11~13]프로그래머스 코딩테스트 Lv.1 문제들 (1) | 2023.01.13 |


